Homemade Machine Learning in Python
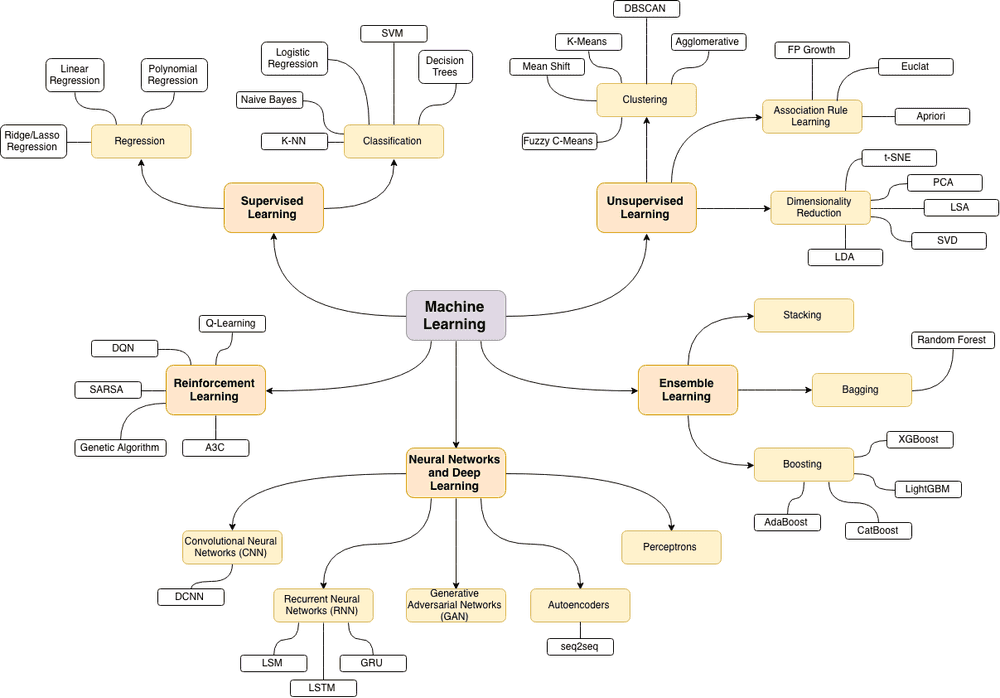
The source of the following machine learning topics map is this wonderful blog post.
I’ve recently launched Homemade Machine Learning repository that contains examples of popular machine learning algorithms and approaches (like linear/logistic regressions, K-Means clustering, neural networks) implemented in Python with mathematics behind them being explained. Each algorithm has interactive Jupyter Notebook demo that allows you to play with training data, algorithms configurations and immediately see the results, charts and predictions right in your browser. In most cases the explanations are based on this great machine learning course by Andrew Ng.
The purpose of the repository was not to implement machine learning algorithms by using 3rd party library “one-liners” but rather to practice implementing these algorithms from scratch and get better understanding of the mathematics behind each algorithm. That’s why all algorithms implementations are called “homemade”.
The main Python libraries that are used there are NumPy and Pandas. These two are used for efficient matrix operations and for loading/parsing CSV datasets. When it comes to Jupyter Notebook demos then such libraries as Matplotlib and Plotly are being used for data visualizations.
Currently, the following topics have been covered:
Regression: Linear Regression
In regression problems we do real value predictions. Basically we try to draw a line/plane/n-dimensional plane along the training examples.
Usage examples: stock price forecast, sales analysis, dependency of any number, etc.
- 📗 Linear Regression Math — theory and links for further readings
- ⚙️ Linear Regression Implementation Example
- ▶️ Demo | Univariate Linear Regression — predict
country happinessscore byeconomy GDP - ▶️ Demo | Multivariate Linear Regression — predict
country happinessscore byeconomy GDPandfreedom index - ▶️ Demo | Non-linear Regression — use linear regression with polynomial and sinusoid features to predict non-linear dependencies.
Classification: Logistic Regression
In classification problems we split input examples by certain characteristic.
Usage examples: spam-filters, language detection, finding similar documents, handwritten letters recognition, etc.
- 📗 Logistic Regression Math — theory and links for further readings
- ⚙️ Logistic Regression Implementation Example
- ▶️ Demo | Logistic Regression (Linear Boundary) — predict Iris flower
classbased onpetal_lengthandpetal_width - ▶️ Demo | Logistic Regression (Non-Linear Boundary) — predict microchip
validitybased onparam_1andparam_2 - ▶️ Demo | Multivariate Logistic Regression — recognize handwritten digits from
28x28pixel images.
Clustering: K-means Algorithm
In clustering problems we split the training examples by unknown characteristics. The algorithm itself decides what characteristic to use for splitting.
Usage examples: market segmentation, social networks analysis, organize computing clusters, astronomical data analysis, image compression, etc.
- 📗 K-means Algorithm Math — theory and links for further readings
- ⚙️ K-means Algorithm Implementation Example
- ▶️ Demo | K-means Algorithm — split Iris flowers into clusters based on
petal_lengthandpetal_width
Neural Networks: Multilayer Perceptron (MLP)
The neural network itself isn’t an algorithm, but rather a framework for many different machine learning algorithms to work together and process complex data inputs.
Usage examples: as a substitute of all other algorithms in general, image recognition, voice recognition, image processing (applying specific style), language translation, etc.
- 📗 Multilayer Perceptron Math — theory and links for further readings
- ⚙️ Multilayer Perceptron Implementation Example
- ▶️ Demo | Multilayer Perceptron — recognize handwritten digits from
28x28pixel images.
Anomaly Detection: Gaussian Distribution
Anomaly detection (also outlier detection) is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data.
Usage examples: intrusion detection, fraud detection, system health monitoring, removing anomalous data from the dataset etc.
I hope you’ll find the repository useful. Either by playing with demos or by reading the math sections or by simply exploring the source code. Happy coding!
Subscribe to the Newsletter
Get my latest posts and project updates by email