Micrograd TS
I recently went through a very detailed and well-explained Python-based project/lesson by karpathy which is called micrograd. This is a tiny scalar-valued autograd engine and a neural net on top of it. This video explains how to build such a network from scratch.
The project above is, as expected, built on Python. For learning purposes, I wanted to see how such a network may be implemented in TypeScript and came up with a 🤖 micrograd-ts repository (and also with a demo of how the network may be trained).
Trying to build anything on your own very often gives you a much better understanding of a topic. So, this was a good exercise, especially taking into account that the whole code is just a ~200 lines of TS code with no external dependencies.
The micrograd-ts repository might be useful for those who want to get a basic understanding of how neural networks work, using a TypeScript environment for experimentation.
With that being said, let me give you some more information about the project.
Project structure
- micrograd/ — this folder is the core/purpose of the repo
- engine.ts — the scalar
Valueclass that supports basic math operations likeadd,sub,div,mul,pow,exp,tanhand has abackward()method that calculates a derivative of the expression, which is required for back-propagation flow. - nn.ts — the
Neuron,Layer, andMLP(multi-layer perceptron) classes that implement a neural network on top of the differentiable scalarValues.
- engine.ts — the scalar
- demo/ - demo React application to experiment with the micrograd code
- src/demos/ - several playgrounds where you can experiment with the
Neuron,Layer, andMLPclasses.
- src/demos/ - several playgrounds where you can experiment with the
Micrograd
See the 🎬 The spelled-out intro to neural networks and back-propagation: building micrograd YouTube video for the detailed explanation of how neural networks and backpropagation work. The video also explains in detail what the Neuron, Layer, MLP, and Value classes do.
Briefly, the Value class allows you to build a computation graph for some expression that consists of scalar values.
Here is an example of how the computation graph for the a * b + c expression looks like:

Based on the Value class we can build a Neuron expression X * W + b. Here we're simulating a dot-product of matrix X (input features) and matrix W (neuron weights):
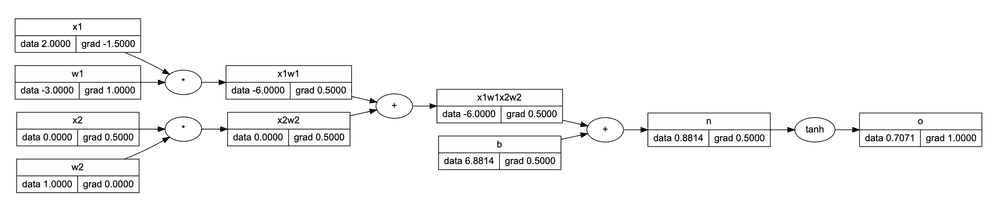
Out of Neurons, we can build the MLP network class that consists of several Layers of Neurons. The computation graph in this case may look a bit complex to be displayed here, but a simplified version might look like this:
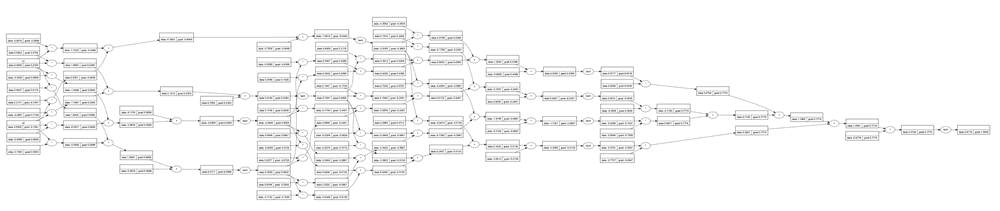
The main idea is that the computation graphs above "know" how to do automatic back propagation (in other words, how to calculate derivatives). This allows us to train the MLP network for several epochs and adjust the network weights in a way that reduces the ultimate loss:
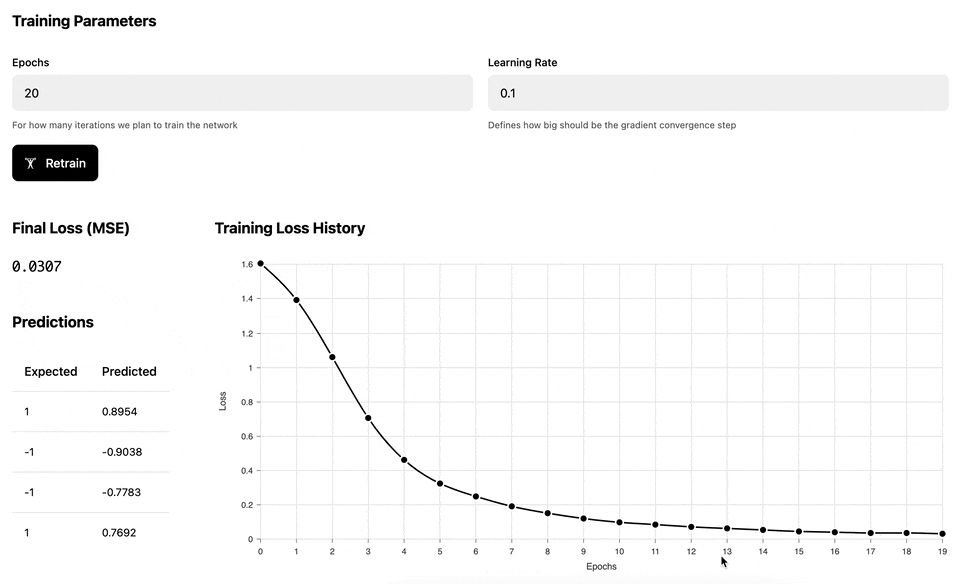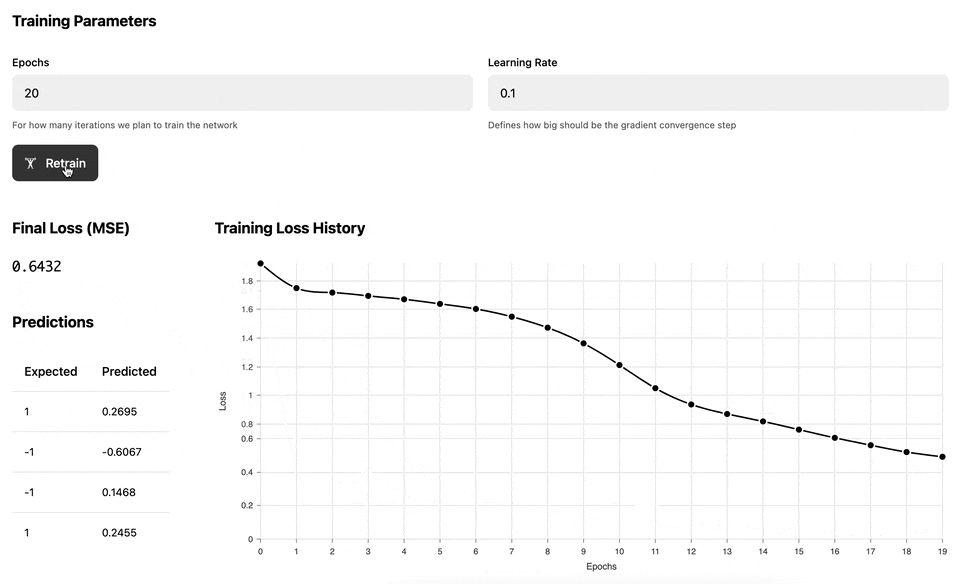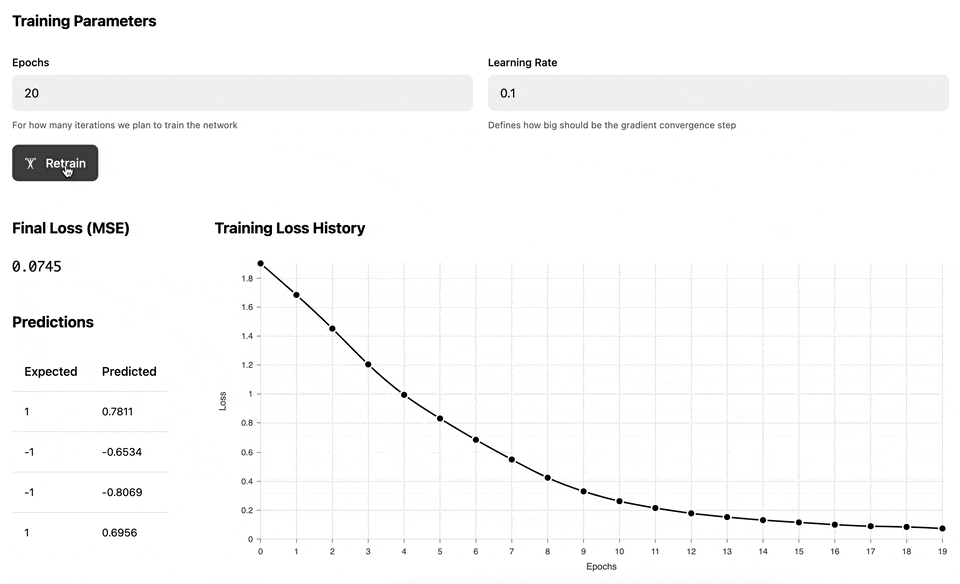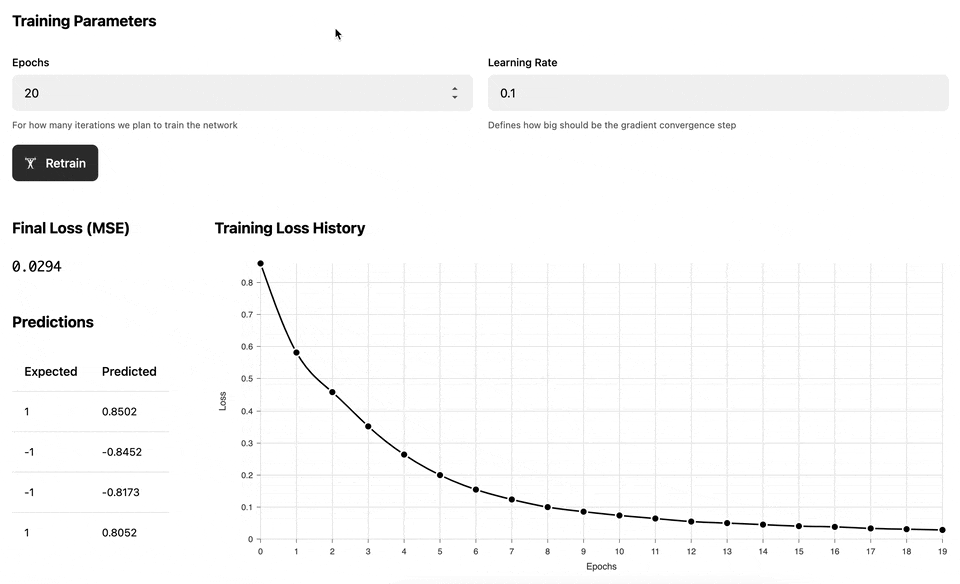
The following demo illustrates the training process of the Multilayer perceptron against a set of dynamically generated "circular" data, where the inner circle has positive labels (1), and the outer circle has negative labels (-1). Once the network has been trained, we test it against a uniform range of data to build a prediction heatmap: the red area is where the model predicts negative values and the green area is where the model predicts positive values.
Demo (online)
To see the online demo/playground, check the following link:
Demo (local)
If you want to experiment with the code locally, follow the instructions below.
Setup
Clone the current repo locally.
Switch to the demo folder:
cd ./demoSetup node v18 using nvm (optional):
nvm useInstall dependencies:
npm iLaunch demo app:
npm run devThe demo app will be available at http://localhost:5173/micrograd-ts
Playgrounds
Go to the ./demo/src/demos/ to explore several playgrounds for the Neuron, Layer, and MLP classes.
I hope, playing around with the micrograd-ts code above and watching the video from Karpathy will be helpful at least for some of you, learners.
🎵 Here is a bit of music-driven MLP training
With a learning rate of 0.3 the training process is stable and converges to the local loss function minimum most of the time.
With a learning rate of 1, you may see how the gradient descent sometimes skips the local minimum by doing the "steps" that are too large. The learning is unstable in this case.
Subscribe to the Newsletter
Get my latest posts and project updates by email